Abstract
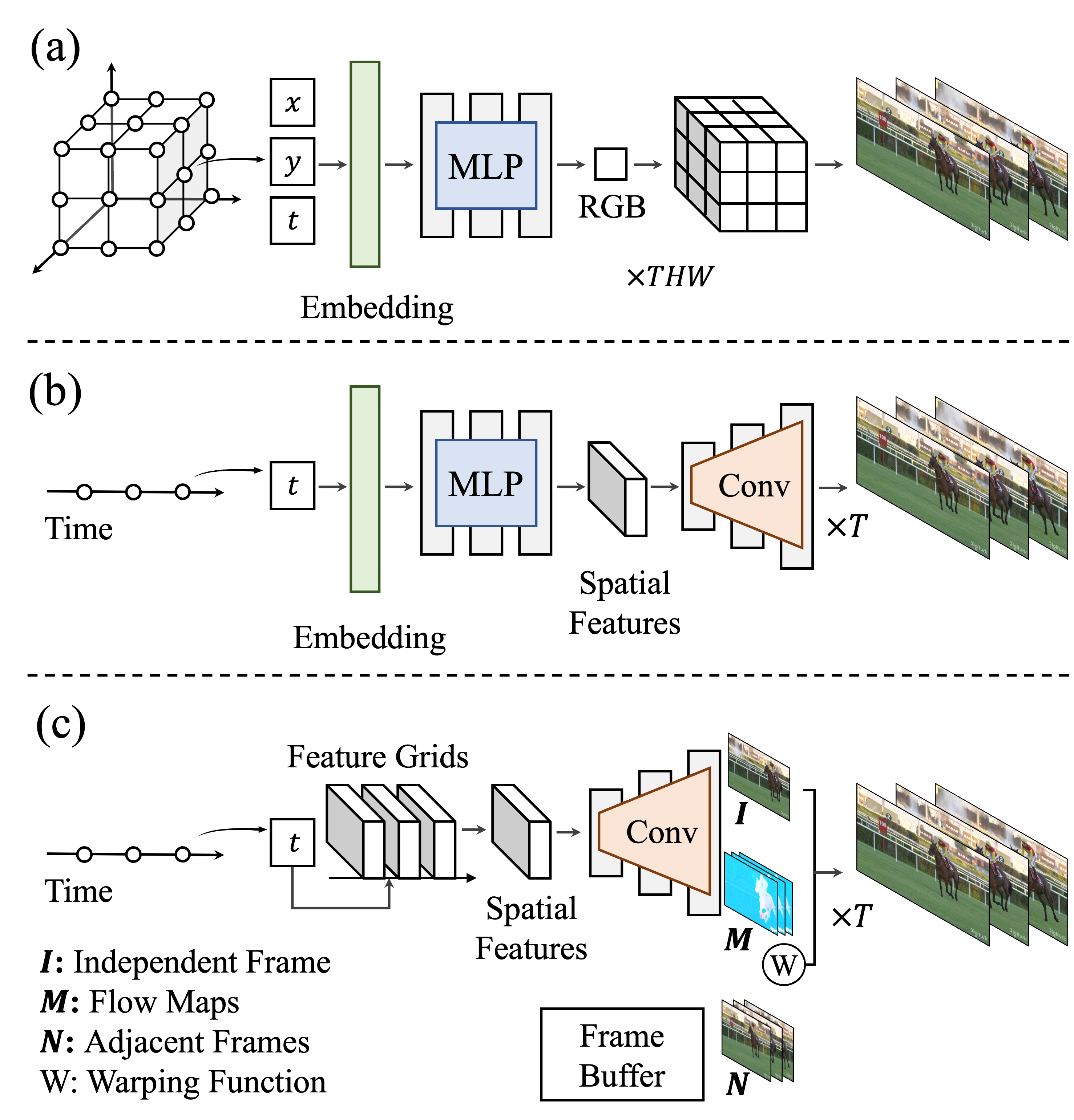
Neural representations have shown a remarkable capability of representing, generating, and manipulating various forms of signals. For videos, however, mapping pixel-wise coordinates to their quantities has shown relatively low compression performance and slow convergence and inference speed (a). Frame-wise video representation, which maps a temporal coordinate to its entire frame (b), has recently emerged as an alternative method to represent videos, improving compression rates and encoding speed. While promising, it has still failed to reach the performance of state-of-the-art video compression algorithms. In this work, we propose FFNeRV (c), a novel method for incorporating flow information into frame-wise representations to exploit the temporal redundancy across the frames in videos inspired by the standard video codecs. Furthermore, we introduce a fully convolutional architecture, enabled by one-dimensional temporal grids, improving the continuity of spatial features.
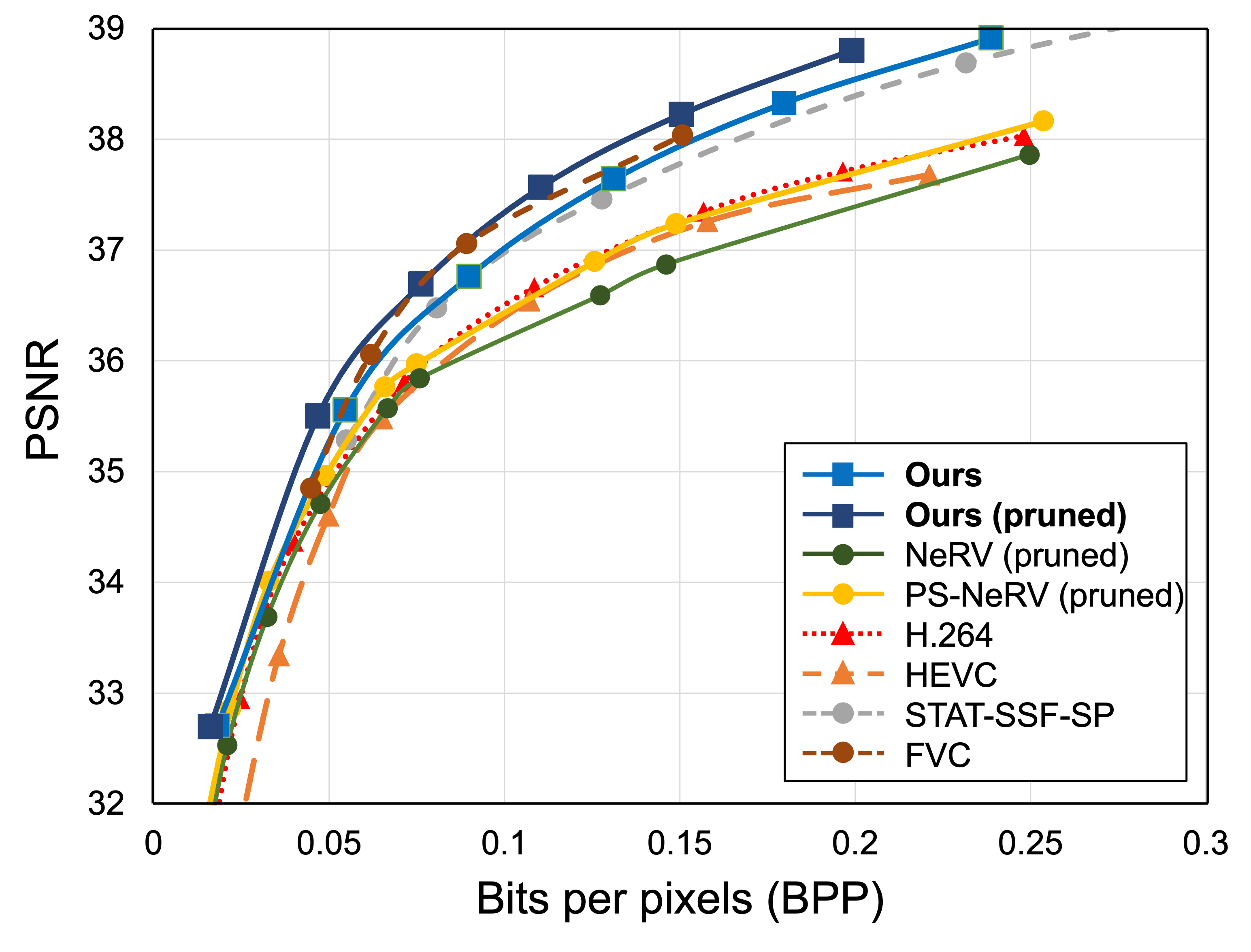
Experimental results show that FFNeRV yields the best performance for video compression and frame interpolation among the methods using frame-wise representations or neural fields. To reduce the model size even further, we devise a more compact convolutional architecture using the group and pointwise convolutions. With all other model compression techniques, including quantization-aware training and entropy coding, FFNeRV outperforms widely-used standard video codecs (H.264 and HEVC) and performs on par with state-of-the-art video compression algorithms.
Method
Inspired by the standard video codecs, we incorporate optical flows into the frame-wise representation to remove the temporal redundancy. FFNeRV generates a video frame by aggregating neighboring frames guided by flows, enforcing the reuse of pixels from other frames. It encourages the network not to waste parameters by memorizing the same pixel values across frames, greatly enhancing parameter efficiency.
Motivated by the grid-based neural representations, we propose to use multi-resolution temporal grids with a fixed spatial resolution to map continuous temporal coordinates to corresponding latent features to further improve the compression performance. We also propose using a more compact convolutional architecture. We employ group and pointwise convolutions in the suggested frame-wise flow representations, motivated by lightweight neural networks and generative models producing high-quality images.
What makes it effective
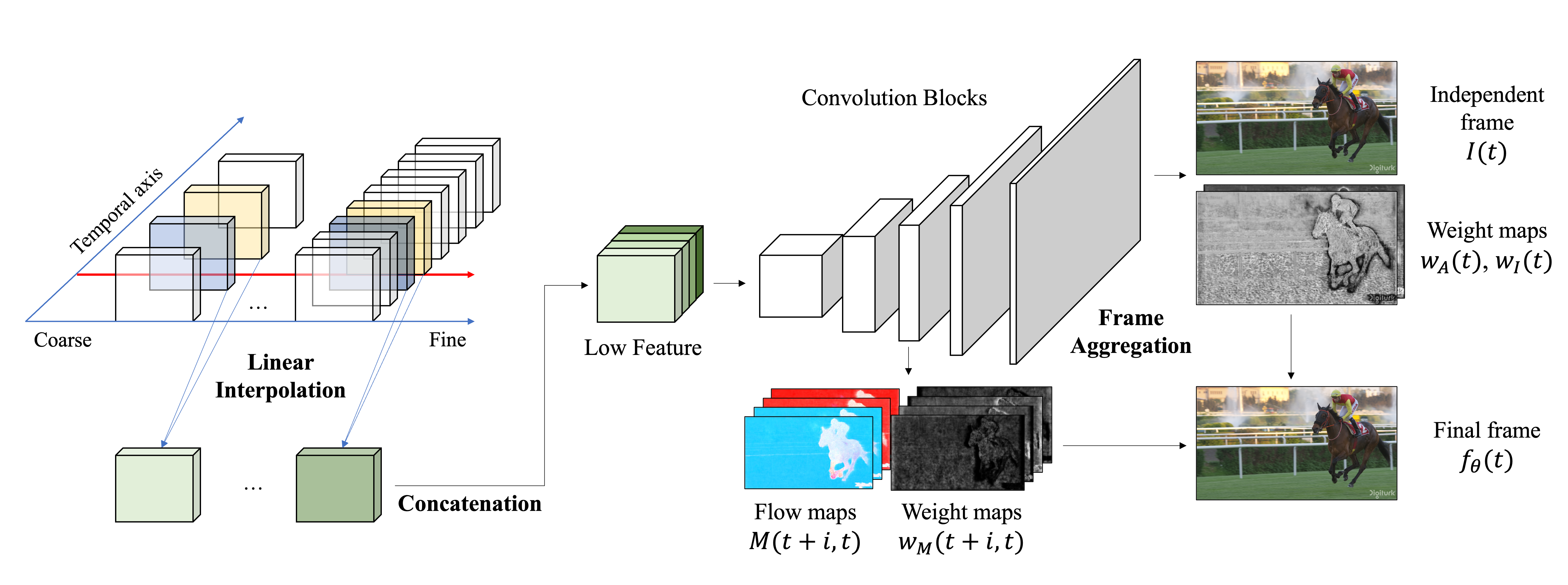
The square area (a) in the following figure is the background and appears constantly in the neighboring frames. Although the independent frame misses this faint part, the aggregated frame captures it by referencing neighboring independent frames. The network adds these missing fine details to the independent frame by retracting those details from nearby frames, as shown in the weight map, in order to improve the quality of the final output. On the other hand, part (b) contains a rapidly moving object, so that the edge of it is blurred when aggregating multiple frames. Hence, the weight pixels corresponding to the part are large for the independent frame. Through the compatibility of the independent and aggregated frames, our approach assures high performance.